
bearbeitet von Salome Lipfert
Die Aufbereitung der REDE-Aufnahmen erfolgte in mehreren aufeinander aufbauenden Arbeitsschritten. Zur Aufbereitung der Sprachaufnahmen wurde das Programm Praat (Version 6.0.19, Boersma/Weenink 1992–2016) verwendet. Mit diesem Programm wurden für einzelnen REDE-Sprachaufnahmen eine eigene TextGrid-Datei erstellt, die im UTF 8 Format gespeichert wurde. Eine TextGrid-Datei kann unterschiedliche Informationen zu einer Sprachaufnahme enthalten. Je nach Informationsart, handelt es sich also z. B. um eine orthographische oder um eine phonetische Transkription der Aufnahme, werden dafür unterschiedliche Tiers angelegt. Ein Tier ist eine Annotationsspur, in der Informationen zur Aufnahme eingegeben werden. Im REDE-Projekt wurden für jede Aufnahme in der Regel mindestens das Tiers OGT und das Tier PIT_PHONWORT angelegt. Insgesamt wurden bis zu sieben Tiers in einer TextGrid-Datei angelegt. Diese Tiers waren: OGT, OGT_klein, ORTHOEPIE, PIT_PHONWORT, PIT_EINZELWORT sowie für die Aufnahmesituationen WS IS und WS IOD zusätzlich die Tiers WS und WS_LEMMAID. Manche TextGrids enthalten auch ein Tier Bemerkungen. Dieses Tier wurde angelegt, wenn zusätzliche Bemerkungen zur Aufnahmesituationen gemacht wurden, z. B. wenn die Aufnahme durch Hintergrundgeräusche gestört wurde.
Abb. 1 zeigt ein Beispiel für eine in Praat geöffnete REDE-Aufnahme mit dem dazugehörigen TextGrid. Die Informationen aus der TextGrid-Datei werden in den unteren sieben Zeilen angegeben. Jede Zeile präsentiert ein Tier, also eine Annotationsspur. In dem Beispiel enthält das TextGrid sieben Tiers, nämlich: WS, OGT, OGT_klein, WS_LEMMAID, PIT_PHONWORT, PIT_EINZELWORT und Bemerkungen.
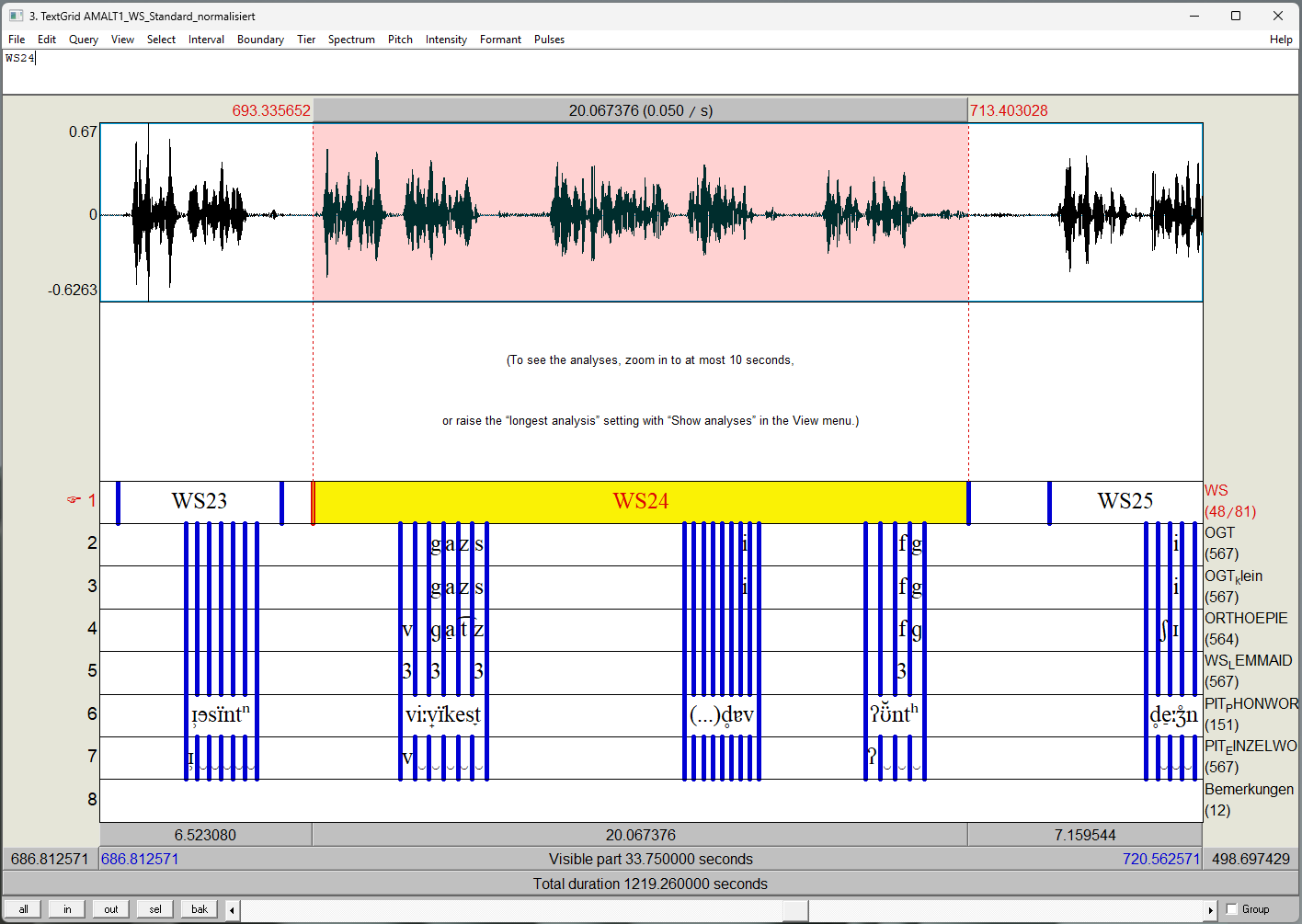
Das Erstellen der TextGrids folgte gewöhnlich einem festgelegten Arbeitsablauf (vgl. Tab. 1). Wie in den jeweiligen Arbeitsschritten im Detail vorgegangen wurde, ist für jeden Arbeitsschritt auf einer eigenen Themenseite beschrieben.
| Themenseite | Tier | WS IS + WS IOD | Interview + Freundesgespräch | Vorlesesprache |
|---|---|---|---|---|
| Sonderfall: WS IS und WS IOD | WS | Wenkersätze alignieren | ||
| TextGrid: Phonetische Tiers | PIT_PHONWORT | phonetische Wörter alignieren | ||
| TextGrid: Orthographische Tiers | OGT | orthographische Transkription der Einzelwörter | ||
| TextGrid: Orthographische Tiers | OGT_klein | orthographische Transkription der Einzelwörter in Kleinbuchstaben, wird automatisch erstellt aus OGT | ||
| TextGrid: Orthoepie | ORTHOEPIE | orthoepische Transkription, wird automatisch erstellt aus OGT | ||
| Sonderfall: WS IS und WS IOD | WS_LEMMAID | Zuordnung der Karten-IDs zu den orthographisch transkribierten Einzelwörtern | ||
| TextGrid: Phonetische Tiers | PIT_PHONWORT | Einfügen der phonetisch-impressionistischen Transkription | ||
| TextGrid: Phonetische Tiers | PIT_EINZELWORT | phonetisch-impressionistischen Transkription der Einzelwörter, wird automatisch erstellt aus PIT_PHONWORT | ||
| Abschlusskontrolle | ||||
Literatur
Boersma, Paul/Weenink, David (1992-2016). Praat: Doing Phonetics by Computer, Version 6.0.19. Online verfügbar unter http://www.praat.org/ (abgerufen am 15.05.2025).