
bearbeitet von Salome Lipfert
PAM steht für das Programm phonetische Abstandsmessung, das im Rahmen des REDE-Projekts entwickelt wurde. Mithilfe des Programms erfolgt die Messung des phonetischen Abstands zwischen einer regionalen Sprachprobe und der kodifizierten Standardsprache bzw. deren Oralisierungsnorm halbautomatisiert. Mit der Messung des phonetischen Abstands zwischen einer regionalen Sprachprobe und ihren standardsprachlichen Bezugselementen ist es möglich, den Dialektalitätsgrad einer Sprachprobe zu quantifizieren und als Dialektalitätswert, kurz D-Wert (vgl. Dialektalitätswertmessung) anzugeben.
Arbeitsschritte bei der phonetischen Abstandsmessung
Um den phonetischen Abstand messen zu können, muss zunächst eine phonetische Transkription der zu messenden Sprachprobe angefertigt werden (vgl. dazu auch die REDE-Transkriptionskonventionen). Um valide Ergebnisse zu erzielen, müssen dabei mindestens 100 Wörter bei Lemmalisten und 150 Wörter in der freien Rede berücksichtigt werden (vgl. Herrgen et al. 2001, 2).
Im REDE-Projekt wurden für die freien Gespräche (Interview und freies Gespräch) sowie für die Standard- und Dialektkompetenzerhebungen ca. 200 Wörter gemessen (vgl. REDE-Aufnahmesituationen). In den freien Gesprächen verteilen sich die Wörter in etwa gleichen Anteilen auf 70 Wörter am Anfang, in der Mitte und am Ende der Aufnahme. Offensichtliche Code-Switching-Passagen wurden davon ausgeschlossen. Der phonetische Abstand in den Standard- und Dialektkompetenzerhebungen (WS ISS und WS IOD) wurde für eine festgelegte Auswahl von 16 Wenkersätzen gemessen. Die Auswahl berücksichtigte die Wenkersätze 1–8, 15, 16, 26, 30, 33, 37, 38, 40. Der Vorlesetext „Nordwind und Sonne“ mit insgesamt etwa 110 Wörtern wurde vollständig berücksichtigt.
Schritt 1: Transkript laden und orthoepische Entsprechung generieren
Für die halbautomatisierte Messung wird zunächst die phonetische Transkription der Sprachprobe als „.textgrid“-Datei in das PAM-Programm geladen (Quelle 1 „laden“, vgl. Abb. 1). Die TextGrid-Datei muss im UTF8-Format abgespeichert sein und in ihrer Tierstruktur den REDE-Konventionen entsprechen. Infos zur Tierstruktur und den einzelnen Aufbereitungsschritten der REDE-Erhebungen sind unter Datenbearbeitung zusammengeführt. Eine ausführliche Anleitung steht im LinguRep des DSA zur Verfügung.
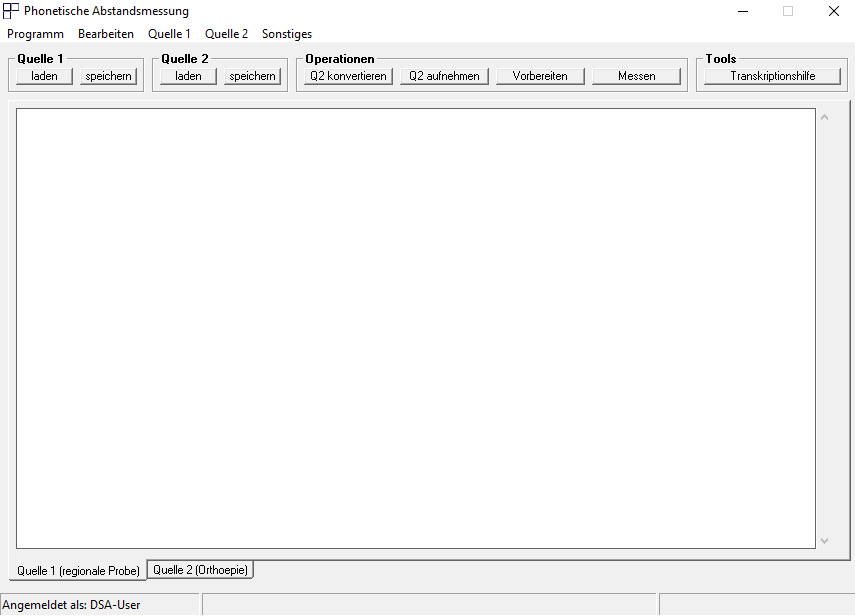
Die phonetische Transkription der regionalen Sprachprobe erscheint nun im Reiter „Quelle 1 (regionale Probe)“ (vgl. Abb. 2).
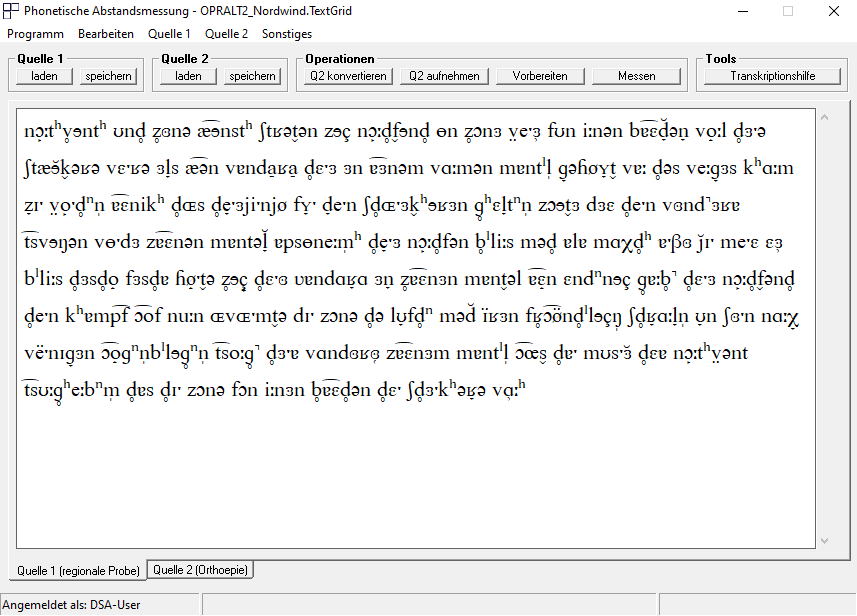
Durch einen Klick auf „Q2 konvertieren“ unter „Operationen“ (vgl. Abb. 2) wird die orthoepische Fassung der regionalen Sprachprobe generiert. Die Orthoepie der regionalen Sprachprobe wird im Reiter „Quelle 2 (Orthoepie)“ angezeigt (vgl. Abb. 3).
Diese ruft das Programm aus einer Aussprachetabelle ab, die aus den Wörterbüchern der Projekte HadiBOMP (Portele et al. 1995) und Verbmobil (Wahlster 2000) erstellt wurde. Da die Aussprachetabellen im SAMPA- bzw. X-SAMPA-Format vorliegen, werden sie nach den REDE-Transkriptionskonventionen automatisch in das IPA-Format konvertiert. Dem Programm unbekannte Wörter werden automatisch mit Sternchen („*“) markiert. Meist handelt es sich dabei um lexikalische oder regionale Varianten. Durch einen Klick auf „Q2 aufnehmen“ kann die Transkription des Worts ergänzt werden. Für eine Umschrift im IPA-Format kann die integrierte Transkriptionshilfe unter „Sonstiges“ >> „Transkriptionshilfe“ aufgerufen werden. Weitere Fehlermeldungen und dazugehörige Lösungen sind in einer eigenen Anleitung zur phonetischen Abstandsmessung beschrieben (vgl. Meinck/Limper 2013).
Schritt 2: Segmentanzahl vergleichen und anpassen
Nachdem die Orthoepie der regionalen Sprachprobe generiert wurde, segmentiert das Programm sowohl die phonetische Transkription der zu messenden regionalen Sprachprobe als auch die daraus generierte Orthoepie in ihre Einzellaute bzw. Segmente und vergleicht wortweise die Segmentanzahlen. Abweichende Segmentanzahlen werden automatisch erkannt und für jedes fehlende Segment wird ein Unterstrich („_“) als Leersegment eingesetzt.
Bei dem automatisierten Vergleich wird immer das erste Segment eines Worts in der regionalen Sprachprobe mit dem ersten Segment seiner orthoepischen Entsprechung verglichen, danach wird das zweite Segment des Worts in der regionalen Sprachprobe mit dem zweiten Segment der orthoepischen Entsprechung verglichen usw. Der Vergleich der Segmentanzahlen und das Einfügen von Leersegmenten geschehen im Hintergrund und sind für die Nutzerin oder den Nutzer nicht sichtbar.
Um sicherzustellen, dass sich in der anschließenden Messung die jeweils richtigen Segmente gegenüberstehen, müssen die automatisch eingefügten Leersegmente von der Nutzerin oder dem Nutzer manuell geprüft werden. Dies geschieht mit einem Klick auf „Vorbereiten“. Danach öffnet sich das Fenster „Segmentanzahl vergleichen“ (vgl. Abb. 4), in dem dazu aufgefordert wird, die Segmente aus der regionalen Sprachprobe mit den Segmenten der orthoepischen Entsprechung wortweise zu vergleichen und die automatisch eingefügten Leersegmente zu bestätigen oder ggf. anzupassen.
Im Feld unter „Quelle 1“ steht die phonetische Transkription des Worts aus der regionalen Sprachprobe und im Feld unter „Quelle 2“ das Wort in seiner orthoepischen Entsprechung (vgl. Abb. 4 für das Wort „Nordwind“).
Wenn alle Wörter mit Leersegmenten geprüft wurden, schließt das Programm automatisch das Fenster „Segmentanzahl vergleichen“ und der Messvorgang kann durch einen Klick auf „Messen“ gestartet werden.
Schritt 3: Messen
Im Messvorgang vergleicht das Programm nun wortweise jedes Segment der regionalen Sprachprobe mit dem jeweiligen gegenübergestellten orthoepischen Segment bzw. Leersegment. Dabei werden sowohl quantitative als auch qualitative Unterschiede berücksichtigt. Die Bearbeitungsreihenfolge ist dabei dieselbe wie beim Vergleich der Segmentanzahlen, das heißt, das erste Segment eines Wortes in der regionalen Sprachprobe wird mit dem ersten Segment seiner orthoepischen Entsprechung verglichen usw.
Damit das Programm die jeweiligen phonetischen Segmente einer Äußerung so beschreiben kann wie es die phonetische Transkription vorgibt, wurde das System der phonetischen Merkmalsstränge entwickelt.
In diesen bilden die einzelnen phonetischen Dimensionen eines Lauts einen Zahlenstrang, der an seinen unterschiedlichen Stellen je nach Merkmalsausprägung der entsprechenden Dimension konfiguriert ist. Die Ausprägungen werden in diesem System durch jeweils eine ein- bis zweistellige Zahl repräsentiert (vgl. Abb. 5).
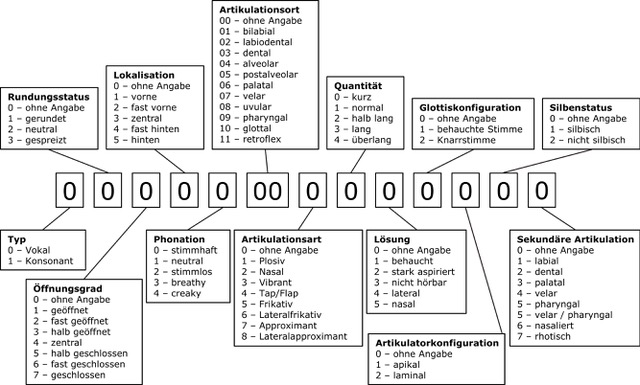
Da die einzelnen Merkmalsausprägungen in den Dimensionen, in denen dies möglich ist, entsprechend ihrer Entfernung zueinander sortiert sind (z. B. in der konsonantischen Dimension Artikulationsart), kann die Messung zwischen zwei Segmenten ganz einfach durch Addition bzw. Subtraktion an den entsprechenden Stellen durchgeführt werden.
Die im REDE-Projekt festgelegten Konventionen zur Punktevergabe für Differenzphänomene sind auf der Themenseite Dialektalitätswertmessung zu finden.
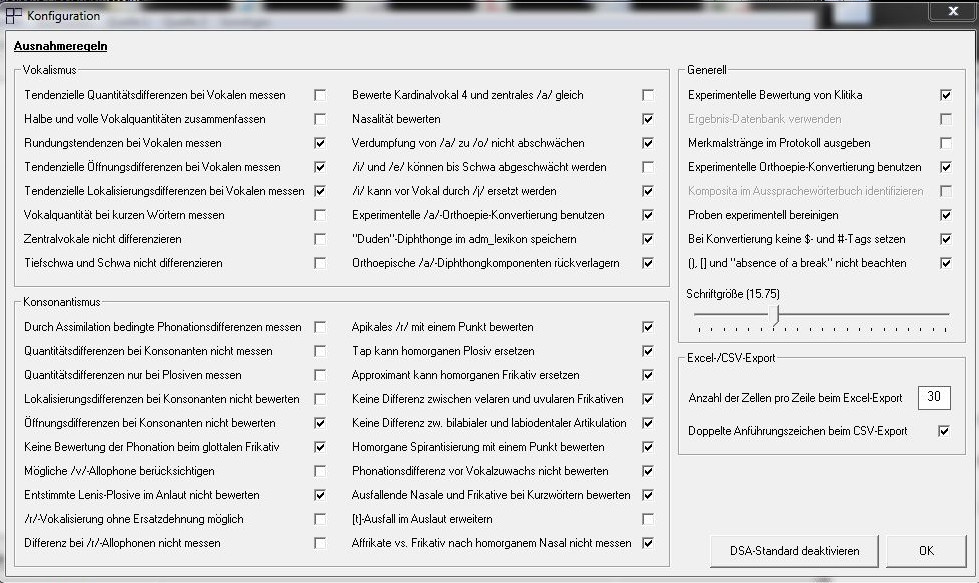
Zusätzlich bietet das Programm PAM die Möglichkeit unter „Sonstiges“ >> „Konfiguration“ individuelle „Ausnahmeregeln“ auszuwählen. Hier kann zum Beispiel festgelegt werden, ob Zentralvokale differenziert bewertet oder Quantitätsdifferenzen bei Konsonanten berücksichtigt werden sollen. Standardmäßig sind die im REDE-Projekt festgelegten Konventionen voreingestellt (vgl. Abb. 6).
Schritt 4: Der PAM-Bericht
Ist die Messung abgeschlossen, erscheint automatisch ein Fenster mit dem „Bericht über erkannte Differenzphänomene“. Darin werden alle erkannten Differenzphänomene mit ihrer entsprechenden Punktewertung aufgeführt. Die Auflistung der gegenübergestellten Segmente erfolgt für eine bessere Lesbarkeit wortweise (vgl. Abb. 7).
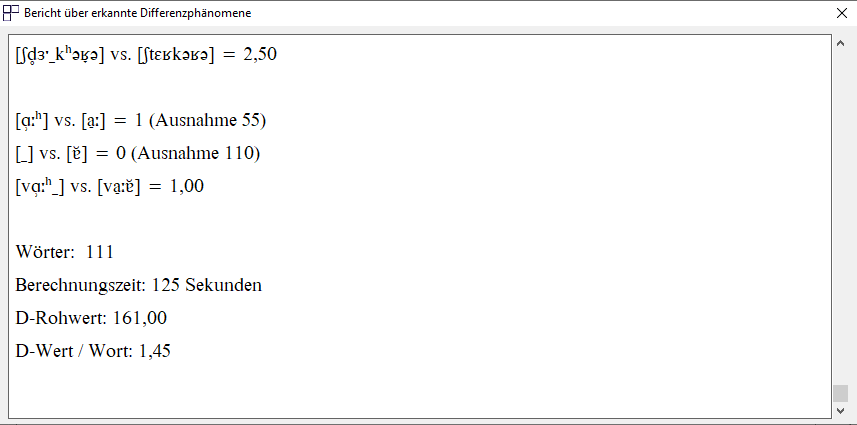
Am Ende des Berichts sind die Anzahl der gemessenen Wörter, der „D-Rohwert“ und der durchschnittliche „D-Wert pro Wort“ angegeben (vgl. Abb. 7). Der D-Rohwert ist die Summe aller vergebenen Punkte. Der durchschnittliche D-Wert (Dialektalitätswert) pro Wort errechnet sich mit dem D-Rohwert dividiert durch die Anzahl der Wörter (vgl. Dialektatlitätswertmessung). In diesem Fall (vgl. Abb. 7) ergibt sich ein D-Wert von 1,45 pro Wort, das heißt, im Durchschnitt weist jedes Wort einen phonetischen Abstand von ca. 1,5 Punkten zur kodifizierten Standardsprache auf.
Der Bericht kann als Reintext (.txt), Excel-Tabelle („.xls“ oder „.xlsx“) oder „.csv“-Datei gespeichert werden.
Das Programm misst den phonetischen Abstand zur kodifizierten Oralisierungsnorm unabhängig davon, ob die Abweichung durch Assimilations-, Reduktions- und Tilgungsprozesse, wie sie besonders in der freien gesprochenen Sprache auftreten und/oder durch regionale Varianten bedingt ist. Um statt eines generalisierenden phonetischen Abstandswert einen Dialektalitätswert zu erhalten, müssen in einer manuellen Messkontrolle realisationsphonetische Phänomene aus der Messung ausgeschlossen werden.
Literatur
Herrgen, Joachim/Lameli, Alfred/Rabanus Stefan/Schmidt, Jürgen Erich (2001). Dialektalität als phonetische Distanz. Ein Verfahren zur Messung standarddivergenter Sprechformen. Online verfügbar unter http://archiv.ub.uni-marburg.de/es/2008/0007/pdf/dialektalitaetsmessung.pdf (abgerufen am 27.06.2023).
Meinck, Bettina/Limper, Juliane (2013). Anleitung zur phonetischen Abstandsmessung (PAM). Text-Version 1.0. Online verfügbar unter https://docplayer.org/22791084-Anleitung-zur-phonetischen-abstandsmessung-pam.html (abgerufen 11.01.2024).
Portele, Thomas/Krämer, Jürgen/Stock, Dieter (1995). Symbolverarbeitung im Sprachsynthesesystem HADIFIX. In: Hoffmann, Rüdiger (Hrsg.). Studientexte zur Sprachkommunikation: Elektronische Sprachsignalverarbeitung 1995. Techn. Univ. Dresden, Dresden, 97–104.
Wahlster, W. (2000). Mobile Speech-to-Speech Translation of Spontaneous Dialogs: An Overview of the Final Verbmobil System. In: Wahlster, W. (Hrsg.). Verbmobil: Foundations of Speech-to-Speech Translation. Artificial Intelligence. Springer, Berlin, Heidelberg. Online verfügbar unter https://doi.org/10.1007/978-3-662-04230-4_1 (abgerufen am 22.01.2024).