
bearbeitet von Marina Frank und Caroline Kleen
Bei der Formantmessung handelt es sich um eine Methode der akustischen Analyse von Sprachdaten. Im REDE-Projekt werden die Formanten für die Erhebungssituationen „Wenkersätze in der intendierten Standardsprache“ (WS ISS), „Wenkersätze im intendierten Ortsdialekt“ (WS IOD) und der Vorlesesprache „Nordwind und Sonne“ gemessen. Dabei werden neben intersituativen auch raumvergleichende Analysen angestrebt und sowohl vertikale wie auch horizontale Variation sichtbar. Damit bildet die Formantanalyse einen neuen, akustischen Zugang zu den REDE-Daten, der bislang weitgehend unberücksichtigt geblieben ist.
Was sind Formanten?
Bei Formanten handelt es sich um Frequenzbereiche im akustischen Signal, die eine besonders hohe Konzentration akustischer Energie aufweisen. Formanten können in einem sogenannten (Breitband-)Spektrogramm visualisiert werden. Dort wird die Zeit, die Frequenz sowie die Intensität eines Signals abgebildet. Die nachstehende Abbildung 1 zeigt ein Oszillogramm (oben) sowie ein Spektrogramm (unten) von der Äußerung Winter (Wenkersatz 1: Im Winter fliegen die trockenen Blätter durch die Luft herum.). Die Formanten werden fortlaufend (von unten nach oben) nummeriert, beginnend beim ersten Formanten F1, der die niedrigsten Werte aufweist, gefolgt von F2, F3 etc.
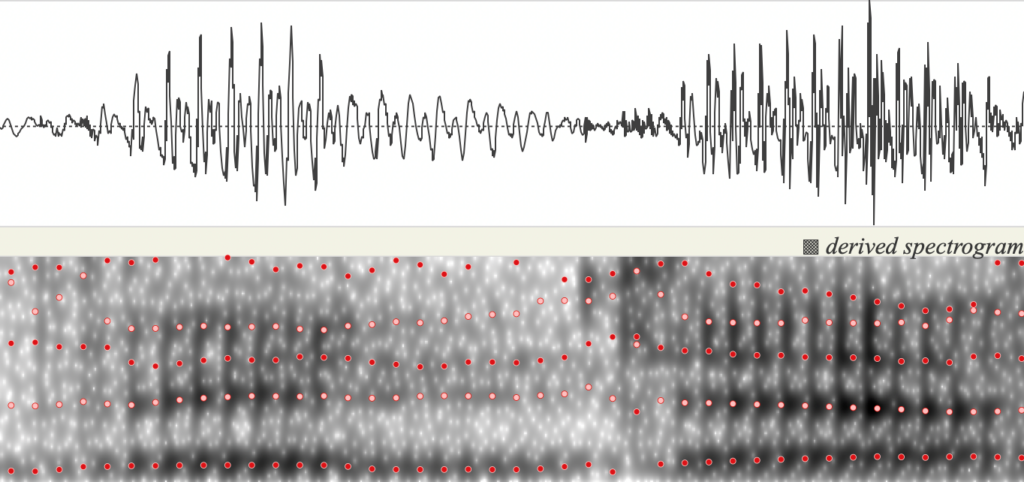
Die beiden ersten Formanten F1 und F2 korrelieren mit artikulatorischen Eigenschaften von Vokalen:
- F1 korreliert mit der Zungenhöhe bzw. Kieferöffnung (je höher F1, desto weiter ist der Kiefer geöffnet)
- F2 korreliert mit der horizontalen Zungenlage (je höher F2, desto weiter vorne im Mund wird der Vokal produziert)
- F3 korreliert tendenziell mit der Lippenrundung und wird daher ebenfalls gemessen, kann in der zweidimensionalen Darstellung allerdings nicht berücksichtigt werden
Formantkarten
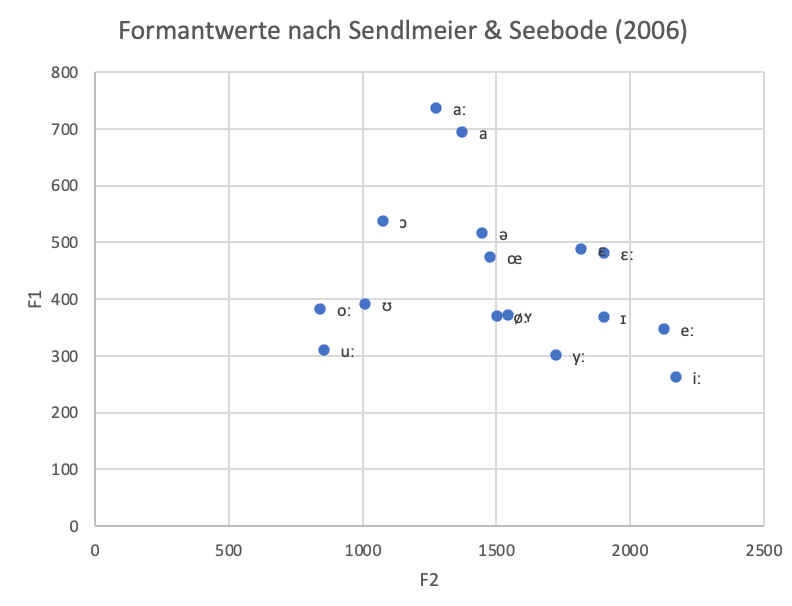
Anhand von gemessenen Formantwerten (für ein Beispiel s. Abb. 2) der verschiedenen Vokale des Deutschen kann ein Diagramm erstellt werden (vgl. Abb. 3).
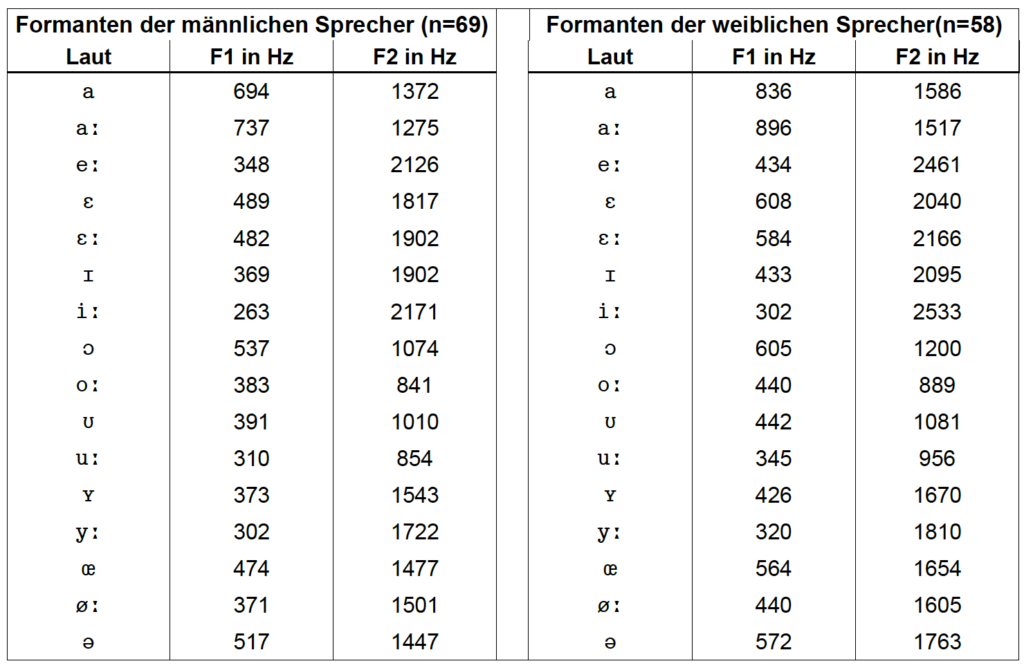
aus Abbildung 2
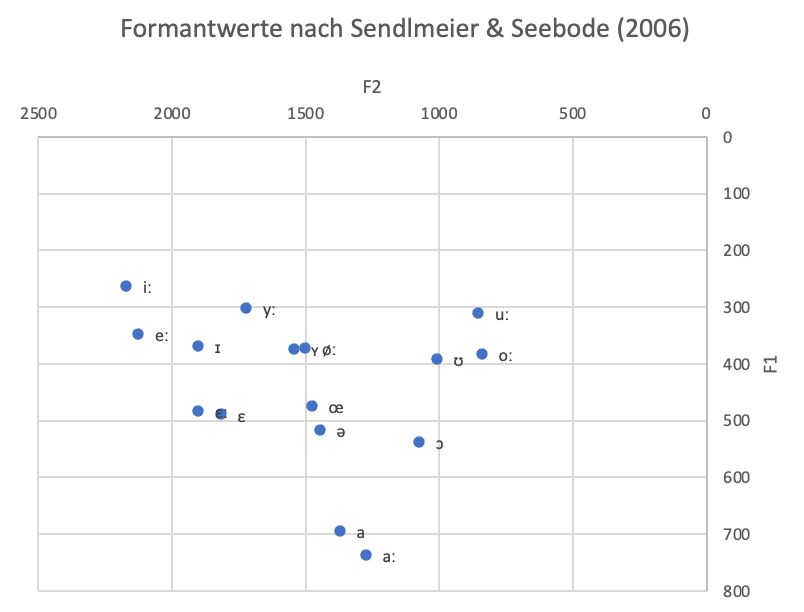
Wenn man die Achsenorientierung des Diagramms so verändert, dass der Nullpunkt nicht mehr links unten, sondern rechts oben ist, dann erhält man eine Darstellung (vgl. Abb. 4), die der artikulatorischen Darstellung im Vokaltrapez der International Phonetic Association (IPA) stark ähnelt (vgl. Abb. 5). Dies verdeutlicht die Korrelation zwischen akustischen und artikulatorischen Eigenschafte bei Vokalen. Die Darstellung in Abbildung 4 wird als Formantkarte bzw. formant chart bezeichnet.

Arbeitsschritte bei der Formantmessung im REDE-Projekt
Das Vorgehen bei der Formantmessung ist für die drei Aufnahmesituationen, also WS ISS, Vorlesetext und WS IOD, ähnlich.
Schritt 1: Erstellen der Datengrundlage
Die Datengrundlage für die Formantmessungen bilden die Tonaufnahmen (WAV-Datei) der drei Aufnahmesituationen WS ISS, Vorlesetext und WS IOD.
Zusätzlich wird zu jeder Tonaufnahme eine TextGrid-Datei benötigt, in der das Gesprochene standardorthographisch verschriftlicht ist. Für die WS ISS und den Vorlesetext kann aus den standardorthographischen TextGrids automatisch eine Textdatei erstellt werden, die für die weitere Aufbereitung zur Formantmessung notwendig ist. Für die WS IOD müssen diese Textdateien manuell angelegt werden. Dabei wird das Gesagte in dialektaler Lautumschrift transliteriert. So lautet der erste Wenkersatz in der deutschen Standardorthographie „Im Winter fliegen die trockenen Blätter in der Luft herum“, im Dialekt von Hirschau (Bayern, Oberpfalz) wird dieser als „im Winte fleing di drucken Bläddl in de Luft ommenant“ wiedergegeben. Wie aus dem Beispiel hervorgeht, wird die Dialektübersetzung nicht phonetisch transkribiert, sondern mit dem deutschen Alphabet verschriftlicht
Schritt 2: Datenaufbereitung mit WebMAUS
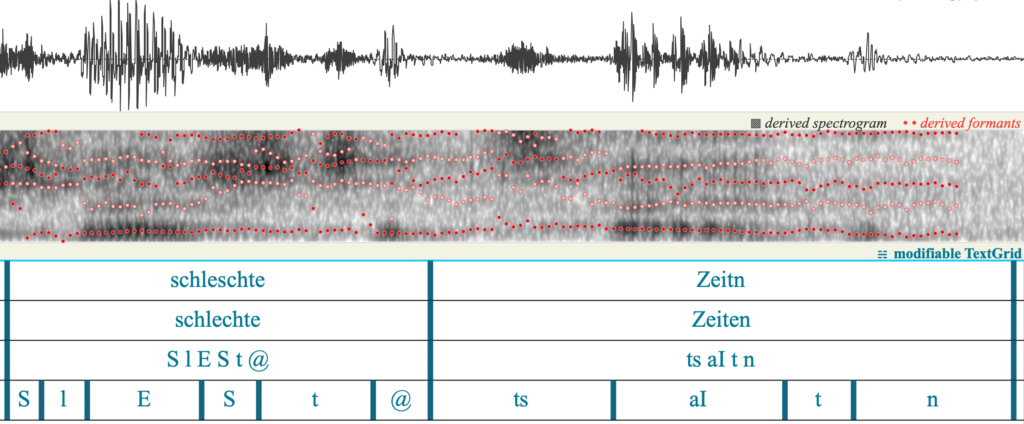
In einem zweiten Schritt wird die Tonaufnahme gemeinsam mit der zugehörigen Textdatei in das BAS-Tool WebMAUS geladen (Schiel 1999). WebMAUS führt anhand der Textdatei eine Graphem-zu-Phonem-Umwandlung durch und ermöglicht so eine automatische Segmentierung der Tonaufnahme auf Lautebene, sodass die Einzellaute im Zeitsignal markiert werden. Das Ergebnis ist ein TextGrid, das drei Zeilen (sog. Tiers) enthält (vgl. Abbildung 6): Ein Tier mit der dialektalen Lautumschrift auf Wortebene, ein Tier mit der Phonem-Zuordnung auf Wortebene (transkribiert in X-SAMPA) und ein Tier mit den Lauten auf Segmentebene (X-SAMPA).
Schritt 3: Korrektur der Segmentgrenzen
Die von WebMAUS automatisch erzeugten Segmentgrenzen müssen anschließend manuell korrigiert werden. Dieser Arbeitsschritt ist erforderlich, da es mitunter vorkommt, dass das Sprachsignal nicht mit dem Transkript übereinstimmt. Die manuellen Korrekturen sind aber vor allem für das korrekte Auslesen der Formantwerte wichtig, d. h. die Segmentgrenzen von Vokalen müssen so gesetzt sein, dass nur der Ausschnitt mit dem Vokal darin enthalten ist. Für die Korrektur wird das Programm Praat (Boersma & Weenink 2023) genutzt.
Im Zuge der manuellen Korrektur wird für die Formantmessung der Aufnahmen WS IOD ein weiteres Tier angelegt. Dieses Tier enthält die geäußerten Wörter in der Standardorthographie. Damit stehen sich die Lautumschrift der dialektintendierten Übersetzung eines Wortes (fleing) im oberen Tier mit seiner standardorthographischen Entsprechung (fliegen) im darunter liegenden Tier gegenüber. Dieses zusätzliche Tier ist notwendig, um für spätere Analysen einen Bezug zwischen Dialektwörtern und standardsprachlichen Wörtern herstellen zu können. Ein Beispiel ist in Abbildung 6 dargestellt:
Schritt 4: Auswertung
Nach der manuellen Korrektur der Segmentgrenzen werden die Formantwerte der Vokale mit einem Praat-Skript automatisch ausgelesen. Für jeden Vokal wird an insgesamt 21 Punkten die Sprechgrundfrequenz (f0) sowie die drei ersten Formanten (F1, F2, F3) gemessen, d. h., zu Beginn des Vokals (0 %), bei 5 % des Vokals, bei 10 % etc. Dies erlaubt die Untersuchung der Formantdynamik, z. B. bei Diphthongen. Die Konsonanten werden in der Ergebnistabelle ebenfalls ausgegeben, um die Analyse des konsonantischen Kontexts zu ermöglichen. Derzeit erfolgt keine akustische Messung der Konsonanten. Das Skript gibt eine Ergebnistabelle aus, die die folgenden Informationen enthält (s. Abb. 7, eine Eröterung zu den Spaltenbezeichnungen in der Ergebnistabelle findet sich am Ende der Seite.)
Die Ergebnistabelle wird dann zur weiteren Analyse und Visualisierung im Statistikprogramm R genutzt (R Core Team 2023), womit Diagramme der Formantwerte erstellt werden können, die die vertikale und horizontale Variation darstellen. Außerdem werden statistische Analysen durchgeführt.
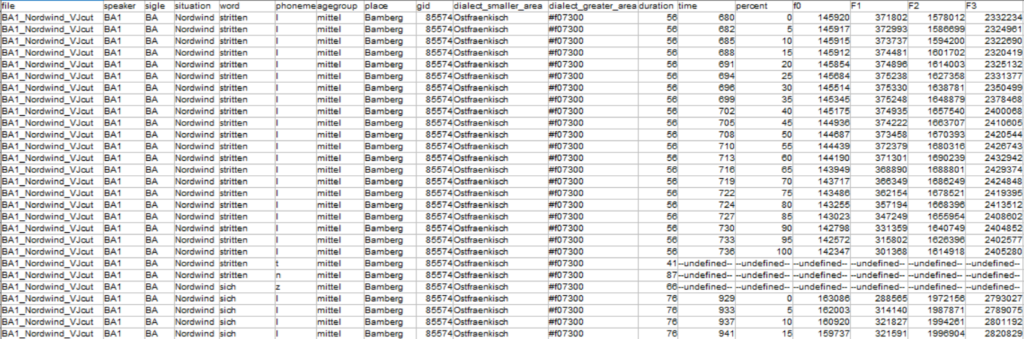
| Spaltenbezeichnung | Erläuterung |
| file | Dateiname |
| speaker | Sprecher-Sigle |
| sigle | Orts-Sigle |
| situation | Aufnahmesituation: WS ISS, Vorlesesprache, WS IOD |
| word | Wort (vgl. Abb. 6 für WS IOD kommt noch eine Spalte mit dem Wort in dialektaler Lautumschrift hinzu) |
| phoneme | Phonem aus dem Tier mit den Lautsegmenten (transkribiert in SAMPA) |
| agegroup | Generation: alt, mittel, jung |
| place | Ort |
| gid | REDE-GID |
| dialect_smaller_area | Dialektregion nach Wiesinger (1983) |
| duration | Dauer des Lautsegments |
| time | Messzeit der Gesamtvokaldauer in Prozent |
| f0 | Sprechgrundfrequenz (f0) |
| F1 | erster Formant (F1) |
| F2 | zweiter Formant (F2) |
| F3 | dritter Formant (F3) |
Aktuelle Ergebnisse der Formantmessungen sind hier publiziert: Kleen, Caroline/Frank, Marina/Lameli, Alfred (2024). Vertical Differences in German Vowel Space Areas. Proceedings of the 5th International Symposium on Applied Phonetics (ISAPh 2024), 43-48. https://www.isca-archive.org/isaph_2024/kleen24_isaph.pdf [zugegriffen am 09.04.2025].
Literatur
Boersma, Paul/David Weenink (2023). Praat: Doing Phonetics by Computer, Version 6.3.15. Online verfügbar unter http://praag.org (abgerufen am 23.08.2023).
R Core Team (2023). R: A language and environment for statistical computing, Version 4.3.1, Vienna: R Foundation for Statistical Computing. Online verfügbar unte https://R-project.org/ (abgerufen am 16.06.2023).
Schiel, Florian (1999). Automatic phonetic transcription of non-prompted speech. In: John J. Ohala (Hrsg.). Proceedings of the XIVth International Congress of Phonetic Sciences 1999. San Francisco, 607–610
Sendlmeier, Walter F./Julia Seebode (2006). Formantkarten des deutschen Vokalsystems. Online verfügbar unter https://www.static.tu.berlin/fileadmin/www/10002019/Forschung/Formantkarten_des_deutschen_Vokalsystems_01.pdf (abgerufen am 01.12.2023).
Wiesinger, Peter (1983). Die Einteilung der deutschen Dialekte. In: Werner Werner Besch/Ulrich Knoop/Wolfgang Putschke et al. (Hg.). Dialektologie. Ein Handbuch zur deutschen und allgemeinen Dialektforschung. Zweiter Halbband. Berlin/New York, Walter de Gruyter, 807–900.