
bearbeitet von Salome Lipfert
Die Aufbereitung der REDE-Aufnahmen erfolgte in mehreren aufeinander aufbauenden Arbeitsschritten. Zur Aufbereitung der Sprachaufnahmen wurde das Programm Praat (Version 6.0.19, Boersma/Weenink 1992-2016) verwendet. Damit wurden für jede Sprachaufnahme eine TextGrid-Datei erstellt, die im UTF 8 Format gespeichert wurde. Zur Vorbereitung für das Erstellen der Tiers OGT und OGT_klein wurden zunächst die Grenzen, sogenannte Boundaries, der phonetischen Wörter, also zusammenhängender Äußerungen ohne längere Pausen, im Tier PIT_PHONWORT gesetzt (vgl. Abb. 1).
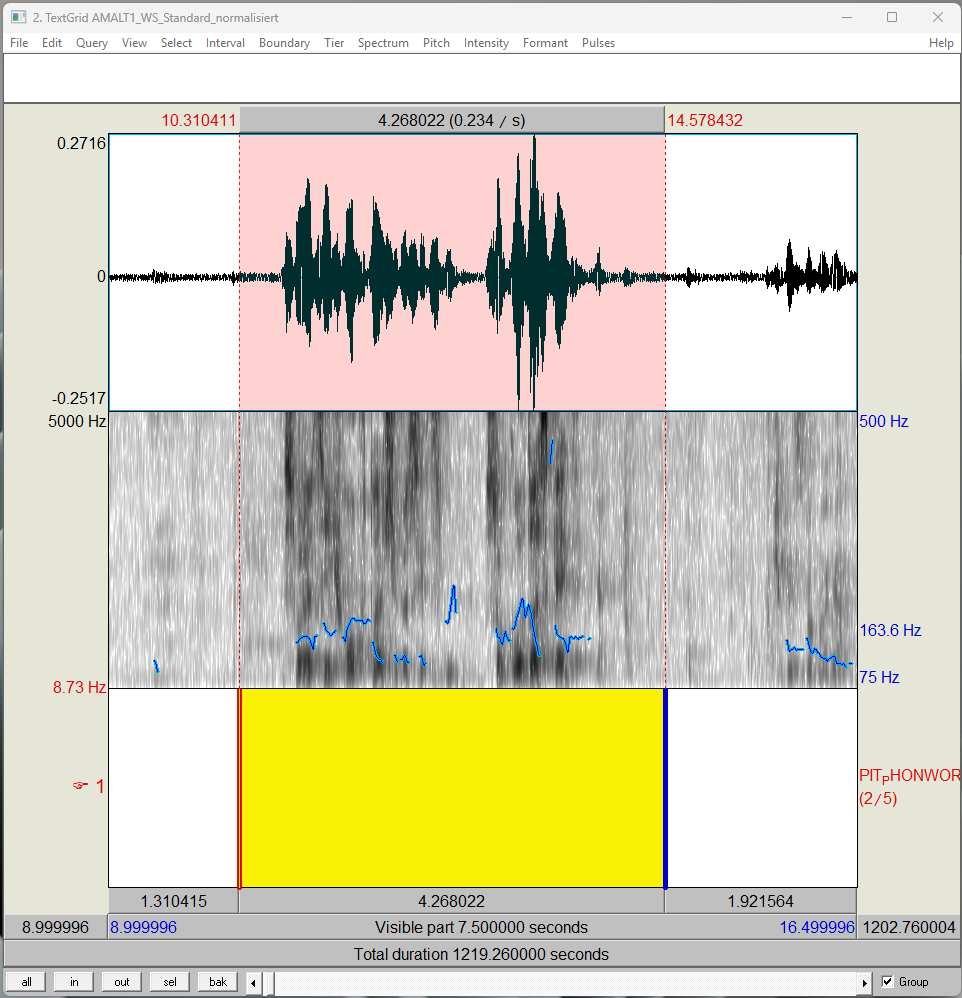
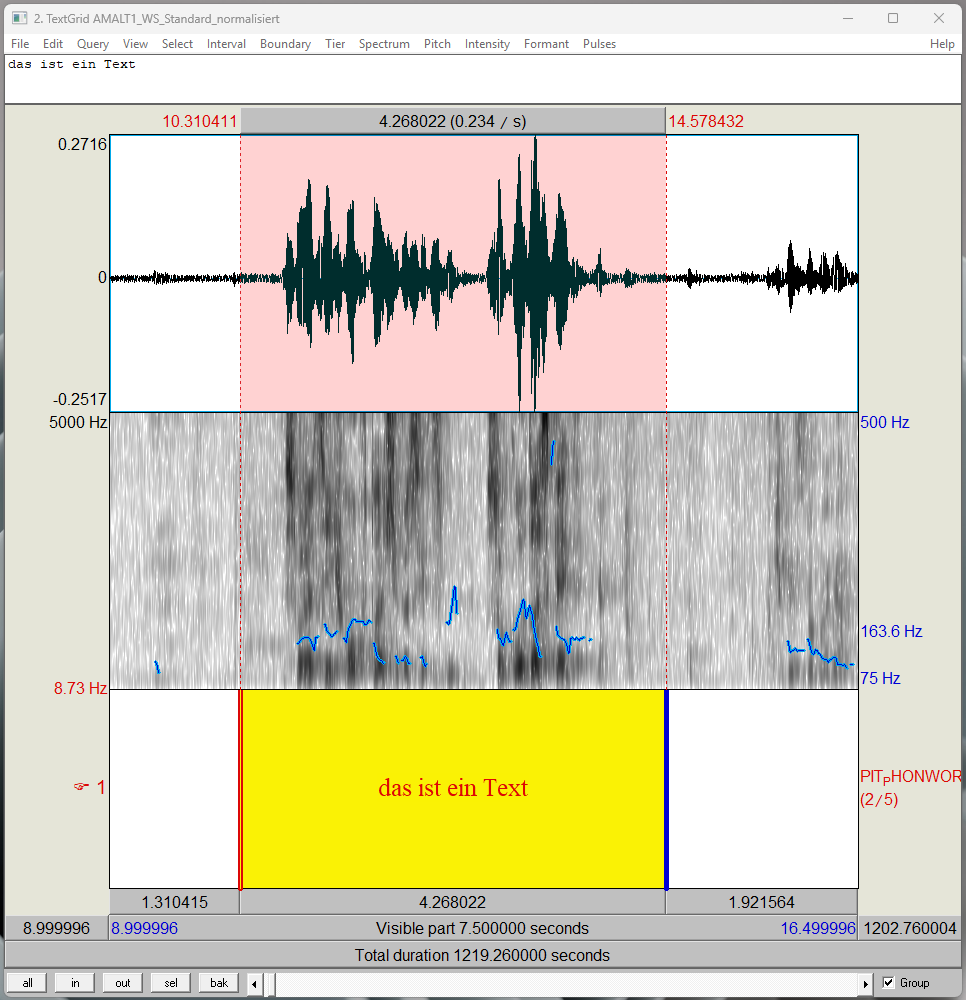
Die Boundaries der Phonwort-Intervalle sollten dabei nicht allzu nah an das Signal gesetzt werden, um sicherzustellen, dass alle Laute gut verständlich sind. Die orthographische Transkription wurde in die im Tier PIT_PHONWORT gesetzten Intervalle eingegeben (vgl. Abb. 1). Anders als im Tier PIT_PHONWORT steht in den Tiers OGT und OGT_klein jedes Wort in einem eigenen Intervall, das heißt vor und nach jedem Wort ist eine Boundary. Das Setzen dieser Boundaries zwischen den Einzelwörtern erfolgte automatisiert mit einem dafür erstellten Praat Skript. Dieses Praat Skript übertrug jedes orthographisch transkribierte Wort aus dem Tier PIT_PHONWORT automatisch in ein eigenes Intervall ins Tier OGT und erzeugte zusätzlich eine OGT in Kleinbuchstaben, die automatisch in das Tier OGT_klein eingefügt wurde. Sobald das Praat Skript die Tiers OGT und OGT_klein gefüllt hat, wurde der Text im Tier PIT_PHONWORT gelöscht. Waren die Tiers OGT und OGT_klein nicht bereits vorab angelegt wurde, erstellte das Praat Skripte diese ebenfalls automatisch (vgl. Abb. 2).
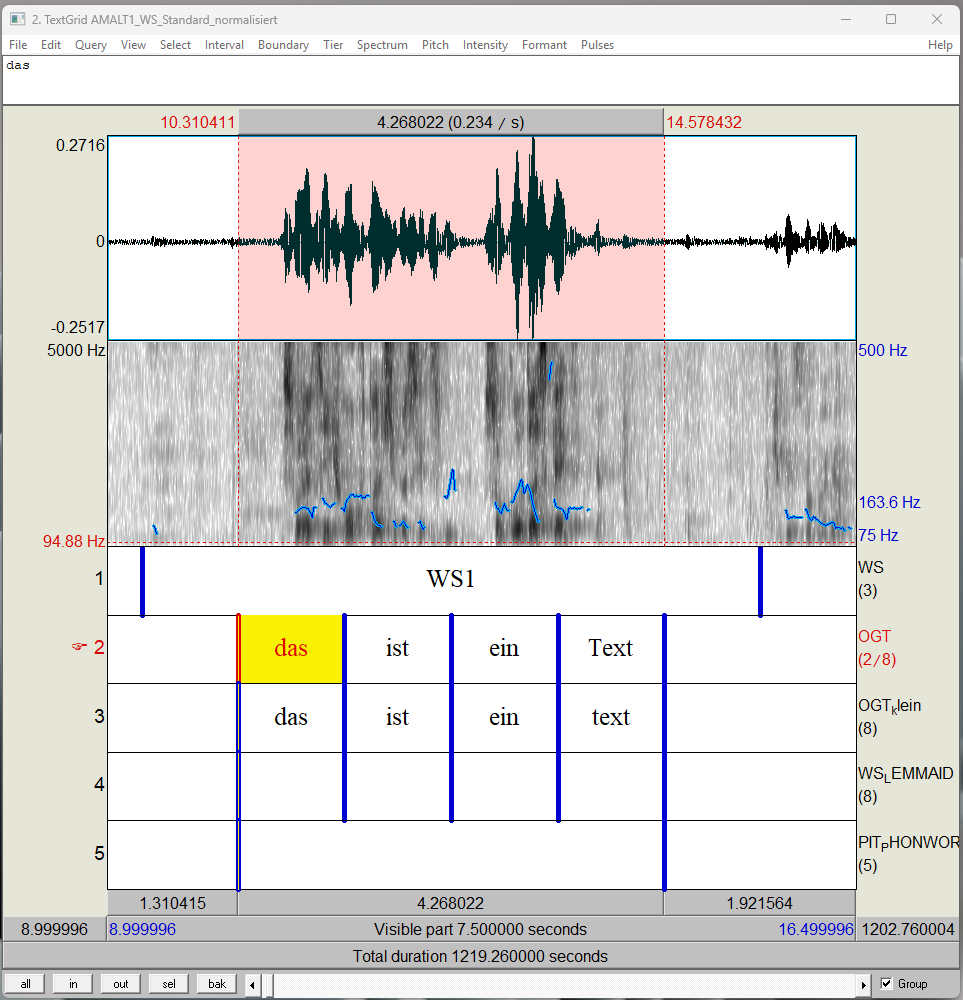
Literatur
Boersma, Paul/Weenink, David (1992-2016). Praat: Doing Phonetics by Computer, Version 6.0.19. Online verfügbar unter http://www.praat.org/ (abgerufen am 15.05.2025).